



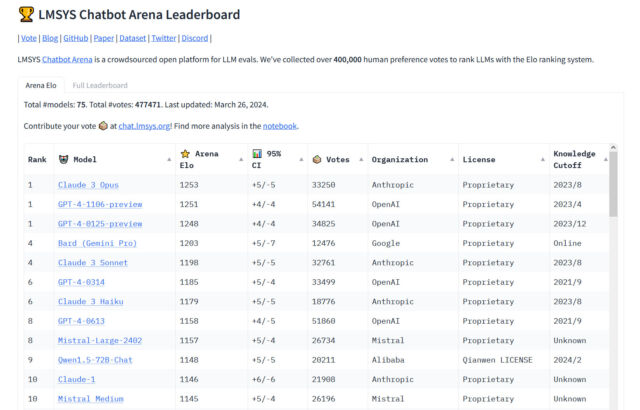
On Tuesday, Anthropic’s Claude 3 Opus giant language mannequin (LLM) surpassed OpenAI’s GPT-4 (which powers ChatGPT) for the primary time on Chatbot Area, a well-liked crowdsourced leaderboard utilized by AI researchers to gauge the relative capabilities of AI language fashions. “The king is useless,” tweeted software program developer Nick Dobos in a put up evaluating GPT-4 Turbo and Claude 3 Opus that has been making the rounds on social media. “RIP GPT-4.”
Since GPT-4 was included in Chatbot Area round Could 10, 2023 (the leaderboard launched Could 3 of that 12 months), variations of GPT-4 have constantly been on the highest of the chart till now, so its defeat within the Area is a notable second within the comparatively quick historical past of AI language fashions. Considered one of Anthropic’s smaller fashions, Haiku, has additionally been turning heads with its efficiency on the leaderboard.
“For the primary time, the most effective obtainable fashions—Opus for superior duties, Haiku for price and effectivity—are from a vendor that is not OpenAI,” unbiased AI researcher Simon Willison advised Ars Technica. “That is reassuring—all of us profit from a range of prime distributors on this area. However GPT-4 is over a 12 months previous at this level, and it took that 12 months for anybody else to catch up.”
Benj Edwards
Chatbot Area is run by Giant Mannequin Techniques Group (LMSYS ORG), a analysis group devoted to open fashions that operates as a collaboration between college students and school at College of California, Berkeley, UC San Diego, and Carnegie Mellon College.
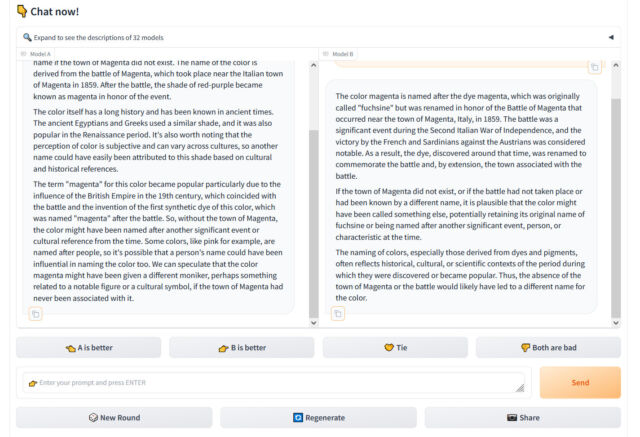
We profiled how the location works in December, however briefly, Chatbot Area presents a person visiting the web site with a chat enter field and two home windows exhibiting output from two unlabeled LLMs. The person’s process it to charge which output is healthier primarily based on any standards the person deems most match. By way of 1000’s of those subjective comparisons, Chatbot Area calculates the “greatest” fashions in mixture and populates the leaderboard, updating it over time.
Chatbot Area is vital as a result of researchers and customers alike usually discover frustration in making an attempt to measure the efficiency of AI chatbots, whose wildly various outputs are tough to quantify. In actual fact, we wrote about how notoriously tough it’s to objectively benchmark LLMs in our information piece concerning the launch of Claude 3. For that story, Willison emphasised the vital position of “vibes,” or subjective emotions, in figuring out the standard of a LLM. “Yet one more case of ‘vibes’ as a key idea in fashionable AI,” he stated.
Benj Edwards
The “vibes” sentiment is frequent within the AI area, the place numerical benchmarks that measure data or test-taking means are often cherry-picked by distributors to make their outcomes look extra favorable. “Simply had an extended coding session with Claude 3 opus and man does it completely crush gpt-4. I don’t suppose normal benchmarks do that mannequin justice,” tweeted AI software program developer Anton Bacaj on March 19.
Claude’s rise might give OpenAI pause, however as Willison talked about, the GPT-4 household itself (though up to date a number of occasions) is over a 12 months previous. At the moment, the Area lists 4 completely different variations of GPT-4, which symbolize incremental updates of the LLM that get frozen in time as a result of every has a novel output fashion, and a few builders utilizing them with OpenAI’s API want consistency so their apps constructed on prime of GPT-4’s outputs do not break.
These embody GPT-4-0314 (the “authentic” model of GPT-4 from March 2023), GPT-4-0613 (a snapshot of GPT-4 from June 13, 2023, with “improved perform calling help,” based on OpenAI), GPT-4-1106-preview (the launch model of GPT-4 Turbo from November 2023), and GPT-4-0125-preview (the newest GPT-4 Turbo mannequin, supposed to cut back instances of “laziness” from January 2024).
Nonetheless, even with 4 GPT-4 fashions on the leaderboard, Anthropic’s Claude 3 fashions have been creeping up the charts constantly since their launch earlier this month. Claude 3’s success amongst AI assistant customers already has some LLM customers changing ChatGPT of their each day workflow, probably consuming away at ChatGPT’s market share. On X, software program developer Pietro Schirano wrote, “Truthfully, the wildest factor about this complete Claude 3 > GPT-4 is how straightforward it’s to simply… change??”
Google’s equally succesful Gemini Superior has been gaining traction as effectively within the AI assistant area. That will put OpenAI on guard for now, however in the long term, the corporate is prepping new fashions. It’s anticipated to launch a significant new successor to GPT-4 Turbo (whether or not named GPT-4.5 or GPT-5) someday this 12 months, probably in the summertime. It is clear that the LLM area will likely be filled with competitors in the meanwhile, which can make for extra attention-grabbing shakeups on the Chatbot Area leaderboard within the months and years to come back.
On Tuesday, Anthropic’s Claude 3 Opus giant language mannequin (LLM) surpassed OpenAI’s GPT-4 (which powers ChatGPT) for the primary time on Chatbot Area, a well-liked crowdsourced leaderboard utilized by AI researchers to gauge the relative capabilities of AI language fashions. “The king is useless,” tweeted software program developer Nick Dobos in a put up evaluating GPT-4 Turbo and Claude 3 Opus that has been making the rounds on social media. “RIP GPT-4.”
Since GPT-4 was included in Chatbot Area round Could 10, 2023 (the leaderboard launched Could 3 of that 12 months), variations of GPT-4 have constantly been on the highest of the chart till now, so its defeat within the Area is a notable second within the comparatively quick historical past of AI language fashions. Considered one of Anthropic’s smaller fashions, Haiku, has additionally been turning heads with its efficiency on the leaderboard.
“For the primary time, the most effective obtainable fashions—Opus for superior duties, Haiku for price and effectivity—are from a vendor that is not OpenAI,” unbiased AI researcher Simon Willison advised Ars Technica. “That is reassuring—all of us profit from a range of prime distributors on this area. However GPT-4 is over a 12 months previous at this level, and it took that 12 months for anybody else to catch up.”
Benj Edwards
Chatbot Area is run by Giant Mannequin Techniques Group (LMSYS ORG), a analysis group devoted to open fashions that operates as a collaboration between college students and school at College of California, Berkeley, UC San Diego, and Carnegie Mellon College.
We profiled how the location works in December, however briefly, Chatbot Area presents a person visiting the web site with a chat enter field and two home windows exhibiting output from two unlabeled LLMs. The person’s process it to charge which output is healthier primarily based on any standards the person deems most match. By way of 1000’s of those subjective comparisons, Chatbot Area calculates the “greatest” fashions in mixture and populates the leaderboard, updating it over time.
Chatbot Area is vital as a result of researchers and customers alike usually discover frustration in making an attempt to measure the efficiency of AI chatbots, whose wildly various outputs are tough to quantify. In actual fact, we wrote about how notoriously tough it’s to objectively benchmark LLMs in our information piece concerning the launch of Claude 3. For that story, Willison emphasised the vital position of “vibes,” or subjective emotions, in figuring out the standard of a LLM. “Yet one more case of ‘vibes’ as a key idea in fashionable AI,” he stated.
Benj Edwards
The “vibes” sentiment is frequent within the AI area, the place numerical benchmarks that measure data or test-taking means are often cherry-picked by distributors to make their outcomes look extra favorable. “Simply had an extended coding session with Claude 3 opus and man does it completely crush gpt-4. I don’t suppose normal benchmarks do that mannequin justice,” tweeted AI software program developer Anton Bacaj on March 19.
Claude’s rise might give OpenAI pause, however as Willison talked about, the GPT-4 household itself (though up to date a number of occasions) is over a 12 months previous. At the moment, the Area lists 4 completely different variations of GPT-4, which symbolize incremental updates of the LLM that get frozen in time as a result of every has a novel output fashion, and a few builders utilizing them with OpenAI’s API want consistency so their apps constructed on prime of GPT-4’s outputs do not break.
These embody GPT-4-0314 (the “authentic” model of GPT-4 from March 2023), GPT-4-0613 (a snapshot of GPT-4 from June 13, 2023, with “improved perform calling help,” based on OpenAI), GPT-4-1106-preview (the launch model of GPT-4 Turbo from November 2023), and GPT-4-0125-preview (the newest GPT-4 Turbo mannequin, supposed to cut back instances of “laziness” from January 2024).
Nonetheless, even with 4 GPT-4 fashions on the leaderboard, Anthropic’s Claude 3 fashions have been creeping up the charts constantly since their launch earlier this month. Claude 3’s success amongst AI assistant customers already has some LLM customers changing ChatGPT of their each day workflow, probably consuming away at ChatGPT’s market share. On X, software program developer Pietro Schirano wrote, “Truthfully, the wildest factor about this complete Claude 3 > GPT-4 is how straightforward it’s to simply… change??”
Google’s equally succesful Gemini Superior has been gaining traction as effectively within the AI assistant area. That will put OpenAI on guard for now, however in the long term, the corporate is prepping new fashions. It’s anticipated to launch a significant new successor to GPT-4 Turbo (whether or not named GPT-4.5 or GPT-5) someday this 12 months, probably in the summertime. It is clear that the LLM area will likely be filled with competitors in the meanwhile, which can make for extra attention-grabbing shakeups on the Chatbot Area leaderboard within the months and years to come back.
On Tuesday, Anthropic’s Claude 3 Opus giant language mannequin (LLM) surpassed OpenAI’s GPT-4 (which powers ChatGPT) for the primary time on Chatbot Area, a well-liked crowdsourced leaderboard utilized by AI researchers to gauge the relative capabilities of AI language fashions. “The king is useless,” tweeted software program developer Nick Dobos in a put up evaluating GPT-4 Turbo and Claude 3 Opus that has been making the rounds on social media. “RIP GPT-4.”
Since GPT-4 was included in Chatbot Area round Could 10, 2023 (the leaderboard launched Could 3 of that 12 months), variations of GPT-4 have constantly been on the highest of the chart till now, so its defeat within the Area is a notable second within the comparatively quick historical past of AI language fashions. Considered one of Anthropic’s smaller fashions, Haiku, has additionally been turning heads with its efficiency on the leaderboard.
“For the primary time, the most effective obtainable fashions—Opus for superior duties, Haiku for price and effectivity—are from a vendor that is not OpenAI,” unbiased AI researcher Simon Willison advised Ars Technica. “That is reassuring—all of us profit from a range of prime distributors on this area. However GPT-4 is over a 12 months previous at this level, and it took that 12 months for anybody else to catch up.”
Benj Edwards
Chatbot Area is run by Giant Mannequin Techniques Group (LMSYS ORG), a analysis group devoted to open fashions that operates as a collaboration between college students and school at College of California, Berkeley, UC San Diego, and Carnegie Mellon College.
We profiled how the location works in December, however briefly, Chatbot Area presents a person visiting the web site with a chat enter field and two home windows exhibiting output from two unlabeled LLMs. The person’s process it to charge which output is healthier primarily based on any standards the person deems most match. By way of 1000’s of those subjective comparisons, Chatbot Area calculates the “greatest” fashions in mixture and populates the leaderboard, updating it over time.
Chatbot Area is vital as a result of researchers and customers alike usually discover frustration in making an attempt to measure the efficiency of AI chatbots, whose wildly various outputs are tough to quantify. In actual fact, we wrote about how notoriously tough it’s to objectively benchmark LLMs in our information piece concerning the launch of Claude 3. For that story, Willison emphasised the vital position of “vibes,” or subjective emotions, in figuring out the standard of a LLM. “Yet one more case of ‘vibes’ as a key idea in fashionable AI,” he stated.
Benj Edwards
The “vibes” sentiment is frequent within the AI area, the place numerical benchmarks that measure data or test-taking means are often cherry-picked by distributors to make their outcomes look extra favorable. “Simply had an extended coding session with Claude 3 opus and man does it completely crush gpt-4. I don’t suppose normal benchmarks do that mannequin justice,” tweeted AI software program developer Anton Bacaj on March 19.
Claude’s rise might give OpenAI pause, however as Willison talked about, the GPT-4 household itself (though up to date a number of occasions) is over a 12 months previous. At the moment, the Area lists 4 completely different variations of GPT-4, which symbolize incremental updates of the LLM that get frozen in time as a result of every has a novel output fashion, and a few builders utilizing them with OpenAI’s API want consistency so their apps constructed on prime of GPT-4’s outputs do not break.
These embody GPT-4-0314 (the “authentic” model of GPT-4 from March 2023), GPT-4-0613 (a snapshot of GPT-4 from June 13, 2023, with “improved perform calling help,” based on OpenAI), GPT-4-1106-preview (the launch model of GPT-4 Turbo from November 2023), and GPT-4-0125-preview (the newest GPT-4 Turbo mannequin, supposed to cut back instances of “laziness” from January 2024).
Nonetheless, even with 4 GPT-4 fashions on the leaderboard, Anthropic’s Claude 3 fashions have been creeping up the charts constantly since their launch earlier this month. Claude 3’s success amongst AI assistant customers already has some LLM customers changing ChatGPT of their each day workflow, probably consuming away at ChatGPT’s market share. On X, software program developer Pietro Schirano wrote, “Truthfully, the wildest factor about this complete Claude 3 > GPT-4 is how straightforward it’s to simply… change??”
Google’s equally succesful Gemini Superior has been gaining traction as effectively within the AI assistant area. That will put OpenAI on guard for now, however in the long term, the corporate is prepping new fashions. It’s anticipated to launch a significant new successor to GPT-4 Turbo (whether or not named GPT-4.5 or GPT-5) someday this 12 months, probably in the summertime. It is clear that the LLM area will likely be filled with competitors in the meanwhile, which can make for extra attention-grabbing shakeups on the Chatbot Area leaderboard within the months and years to come back.
On Tuesday, Anthropic’s Claude 3 Opus giant language mannequin (LLM) surpassed OpenAI’s GPT-4 (which powers ChatGPT) for the primary time on Chatbot Area, a well-liked crowdsourced leaderboard utilized by AI researchers to gauge the relative capabilities of AI language fashions. “The king is useless,” tweeted software program developer Nick Dobos in a put up evaluating GPT-4 Turbo and Claude 3 Opus that has been making the rounds on social media. “RIP GPT-4.”
Since GPT-4 was included in Chatbot Area round Could 10, 2023 (the leaderboard launched Could 3 of that 12 months), variations of GPT-4 have constantly been on the highest of the chart till now, so its defeat within the Area is a notable second within the comparatively quick historical past of AI language fashions. Considered one of Anthropic’s smaller fashions, Haiku, has additionally been turning heads with its efficiency on the leaderboard.
“For the primary time, the most effective obtainable fashions—Opus for superior duties, Haiku for price and effectivity—are from a vendor that is not OpenAI,” unbiased AI researcher Simon Willison advised Ars Technica. “That is reassuring—all of us profit from a range of prime distributors on this area. However GPT-4 is over a 12 months previous at this level, and it took that 12 months for anybody else to catch up.”
Benj Edwards
Chatbot Area is run by Giant Mannequin Techniques Group (LMSYS ORG), a analysis group devoted to open fashions that operates as a collaboration between college students and school at College of California, Berkeley, UC San Diego, and Carnegie Mellon College.
We profiled how the location works in December, however briefly, Chatbot Area presents a person visiting the web site with a chat enter field and two home windows exhibiting output from two unlabeled LLMs. The person’s process it to charge which output is healthier primarily based on any standards the person deems most match. By way of 1000’s of those subjective comparisons, Chatbot Area calculates the “greatest” fashions in mixture and populates the leaderboard, updating it over time.
Chatbot Area is vital as a result of researchers and customers alike usually discover frustration in making an attempt to measure the efficiency of AI chatbots, whose wildly various outputs are tough to quantify. In actual fact, we wrote about how notoriously tough it’s to objectively benchmark LLMs in our information piece concerning the launch of Claude 3. For that story, Willison emphasised the vital position of “vibes,” or subjective emotions, in figuring out the standard of a LLM. “Yet one more case of ‘vibes’ as a key idea in fashionable AI,” he stated.
Benj Edwards
The “vibes” sentiment is frequent within the AI area, the place numerical benchmarks that measure data or test-taking means are often cherry-picked by distributors to make their outcomes look extra favorable. “Simply had an extended coding session with Claude 3 opus and man does it completely crush gpt-4. I don’t suppose normal benchmarks do that mannequin justice,” tweeted AI software program developer Anton Bacaj on March 19.
Claude’s rise might give OpenAI pause, however as Willison talked about, the GPT-4 household itself (though up to date a number of occasions) is over a 12 months previous. At the moment, the Area lists 4 completely different variations of GPT-4, which symbolize incremental updates of the LLM that get frozen in time as a result of every has a novel output fashion, and a few builders utilizing them with OpenAI’s API want consistency so their apps constructed on prime of GPT-4’s outputs do not break.
These embody GPT-4-0314 (the “authentic” model of GPT-4 from March 2023), GPT-4-0613 (a snapshot of GPT-4 from June 13, 2023, with “improved perform calling help,” based on OpenAI), GPT-4-1106-preview (the launch model of GPT-4 Turbo from November 2023), and GPT-4-0125-preview (the newest GPT-4 Turbo mannequin, supposed to cut back instances of “laziness” from January 2024).
Nonetheless, even with 4 GPT-4 fashions on the leaderboard, Anthropic’s Claude 3 fashions have been creeping up the charts constantly since their launch earlier this month. Claude 3’s success amongst AI assistant customers already has some LLM customers changing ChatGPT of their each day workflow, probably consuming away at ChatGPT’s market share. On X, software program developer Pietro Schirano wrote, “Truthfully, the wildest factor about this complete Claude 3 > GPT-4 is how straightforward it’s to simply… change??”
Google’s equally succesful Gemini Superior has been gaining traction as effectively within the AI assistant area. That will put OpenAI on guard for now, however in the long term, the corporate is prepping new fashions. It’s anticipated to launch a significant new successor to GPT-4 Turbo (whether or not named GPT-4.5 or GPT-5) someday this 12 months, probably in the summertime. It is clear that the LLM area will likely be filled with competitors in the meanwhile, which can make for extra attention-grabbing shakeups on the Chatbot Area leaderboard within the months and years to come back.
On Tuesday, Anthropic’s Claude 3 Opus giant language mannequin (LLM) surpassed OpenAI’s GPT-4 (which powers ChatGPT) for the primary time on Chatbot Area, a well-liked crowdsourced leaderboard utilized by AI researchers to gauge the relative capabilities of AI language fashions. “The king is useless,” tweeted software program developer Nick Dobos in a put up evaluating GPT-4 Turbo and Claude 3 Opus that has been making the rounds on social media. “RIP GPT-4.”
Since GPT-4 was included in Chatbot Area round Could 10, 2023 (the leaderboard launched Could 3 of that 12 months), variations of GPT-4 have constantly been on the highest of the chart till now, so its defeat within the Area is a notable second within the comparatively quick historical past of AI language fashions. Considered one of Anthropic’s smaller fashions, Haiku, has additionally been turning heads with its efficiency on the leaderboard.
“For the primary time, the most effective obtainable fashions—Opus for superior duties, Haiku for price and effectivity—are from a vendor that is not OpenAI,” unbiased AI researcher Simon Willison advised Ars Technica. “That is reassuring—all of us profit from a range of prime distributors on this area. However GPT-4 is over a 12 months previous at this level, and it took that 12 months for anybody else to catch up.”
Benj Edwards
Chatbot Area is run by Giant Mannequin Techniques Group (LMSYS ORG), a analysis group devoted to open fashions that operates as a collaboration between college students and school at College of California, Berkeley, UC San Diego, and Carnegie Mellon College.
We profiled how the location works in December, however briefly, Chatbot Area presents a person visiting the web site with a chat enter field and two home windows exhibiting output from two unlabeled LLMs. The person’s process it to charge which output is healthier primarily based on any standards the person deems most match. By way of 1000’s of those subjective comparisons, Chatbot Area calculates the “greatest” fashions in mixture and populates the leaderboard, updating it over time.
Chatbot Area is vital as a result of researchers and customers alike usually discover frustration in making an attempt to measure the efficiency of AI chatbots, whose wildly various outputs are tough to quantify. In actual fact, we wrote about how notoriously tough it’s to objectively benchmark LLMs in our information piece concerning the launch of Claude 3. For that story, Willison emphasised the vital position of “vibes,” or subjective emotions, in figuring out the standard of a LLM. “Yet one more case of ‘vibes’ as a key idea in fashionable AI,” he stated.
Benj Edwards
The “vibes” sentiment is frequent within the AI area, the place numerical benchmarks that measure data or test-taking means are often cherry-picked by distributors to make their outcomes look extra favorable. “Simply had an extended coding session with Claude 3 opus and man does it completely crush gpt-4. I don’t suppose normal benchmarks do that mannequin justice,” tweeted AI software program developer Anton Bacaj on March 19.
Claude’s rise might give OpenAI pause, however as Willison talked about, the GPT-4 household itself (though up to date a number of occasions) is over a 12 months previous. At the moment, the Area lists 4 completely different variations of GPT-4, which symbolize incremental updates of the LLM that get frozen in time as a result of every has a novel output fashion, and a few builders utilizing them with OpenAI’s API want consistency so their apps constructed on prime of GPT-4’s outputs do not break.
These embody GPT-4-0314 (the “authentic” model of GPT-4 from March 2023), GPT-4-0613 (a snapshot of GPT-4 from June 13, 2023, with “improved perform calling help,” based on OpenAI), GPT-4-1106-preview (the launch model of GPT-4 Turbo from November 2023), and GPT-4-0125-preview (the newest GPT-4 Turbo mannequin, supposed to cut back instances of “laziness” from January 2024).
Nonetheless, even with 4 GPT-4 fashions on the leaderboard, Anthropic’s Claude 3 fashions have been creeping up the charts constantly since their launch earlier this month. Claude 3’s success amongst AI assistant customers already has some LLM customers changing ChatGPT of their each day workflow, probably consuming away at ChatGPT’s market share. On X, software program developer Pietro Schirano wrote, “Truthfully, the wildest factor about this complete Claude 3 > GPT-4 is how straightforward it’s to simply… change??”
Google’s equally succesful Gemini Superior has been gaining traction as effectively within the AI assistant area. That will put OpenAI on guard for now, however in the long term, the corporate is prepping new fashions. It’s anticipated to launch a significant new successor to GPT-4 Turbo (whether or not named GPT-4.5 or GPT-5) someday this 12 months, probably in the summertime. It is clear that the LLM area will likely be filled with competitors in the meanwhile, which can make for extra attention-grabbing shakeups on the Chatbot Area leaderboard within the months and years to come back.
On Tuesday, Anthropic’s Claude 3 Opus giant language mannequin (LLM) surpassed OpenAI’s GPT-4 (which powers ChatGPT) for the primary time on Chatbot Area, a well-liked crowdsourced leaderboard utilized by AI researchers to gauge the relative capabilities of AI language fashions. “The king is useless,” tweeted software program developer Nick Dobos in a put up evaluating GPT-4 Turbo and Claude 3 Opus that has been making the rounds on social media. “RIP GPT-4.”
Since GPT-4 was included in Chatbot Area round Could 10, 2023 (the leaderboard launched Could 3 of that 12 months), variations of GPT-4 have constantly been on the highest of the chart till now, so its defeat within the Area is a notable second within the comparatively quick historical past of AI language fashions. Considered one of Anthropic’s smaller fashions, Haiku, has additionally been turning heads with its efficiency on the leaderboard.
“For the primary time, the most effective obtainable fashions—Opus for superior duties, Haiku for price and effectivity—are from a vendor that is not OpenAI,” unbiased AI researcher Simon Willison advised Ars Technica. “That is reassuring—all of us profit from a range of prime distributors on this area. However GPT-4 is over a 12 months previous at this level, and it took that 12 months for anybody else to catch up.”
Benj Edwards
Chatbot Area is run by Giant Mannequin Techniques Group (LMSYS ORG), a analysis group devoted to open fashions that operates as a collaboration between college students and school at College of California, Berkeley, UC San Diego, and Carnegie Mellon College.
We profiled how the location works in December, however briefly, Chatbot Area presents a person visiting the web site with a chat enter field and two home windows exhibiting output from two unlabeled LLMs. The person’s process it to charge which output is healthier primarily based on any standards the person deems most match. By way of 1000’s of those subjective comparisons, Chatbot Area calculates the “greatest” fashions in mixture and populates the leaderboard, updating it over time.
Chatbot Area is vital as a result of researchers and customers alike usually discover frustration in making an attempt to measure the efficiency of AI chatbots, whose wildly various outputs are tough to quantify. In actual fact, we wrote about how notoriously tough it’s to objectively benchmark LLMs in our information piece concerning the launch of Claude 3. For that story, Willison emphasised the vital position of “vibes,” or subjective emotions, in figuring out the standard of a LLM. “Yet one more case of ‘vibes’ as a key idea in fashionable AI,” he stated.
Benj Edwards
The “vibes” sentiment is frequent within the AI area, the place numerical benchmarks that measure data or test-taking means are often cherry-picked by distributors to make their outcomes look extra favorable. “Simply had an extended coding session with Claude 3 opus and man does it completely crush gpt-4. I don’t suppose normal benchmarks do that mannequin justice,” tweeted AI software program developer Anton Bacaj on March 19.
Claude’s rise might give OpenAI pause, however as Willison talked about, the GPT-4 household itself (though up to date a number of occasions) is over a 12 months previous. At the moment, the Area lists 4 completely different variations of GPT-4, which symbolize incremental updates of the LLM that get frozen in time as a result of every has a novel output fashion, and a few builders utilizing them with OpenAI’s API want consistency so their apps constructed on prime of GPT-4’s outputs do not break.
These embody GPT-4-0314 (the “authentic” model of GPT-4 from March 2023), GPT-4-0613 (a snapshot of GPT-4 from June 13, 2023, with “improved perform calling help,” based on OpenAI), GPT-4-1106-preview (the launch model of GPT-4 Turbo from November 2023), and GPT-4-0125-preview (the newest GPT-4 Turbo mannequin, supposed to cut back instances of “laziness” from January 2024).
Nonetheless, even with 4 GPT-4 fashions on the leaderboard, Anthropic’s Claude 3 fashions have been creeping up the charts constantly since their launch earlier this month. Claude 3’s success amongst AI assistant customers already has some LLM customers changing ChatGPT of their each day workflow, probably consuming away at ChatGPT’s market share. On X, software program developer Pietro Schirano wrote, “Truthfully, the wildest factor about this complete Claude 3 > GPT-4 is how straightforward it’s to simply… change??”
Google’s equally succesful Gemini Superior has been gaining traction as effectively within the AI assistant area. That will put OpenAI on guard for now, however in the long term, the corporate is prepping new fashions. It’s anticipated to launch a significant new successor to GPT-4 Turbo (whether or not named GPT-4.5 or GPT-5) someday this 12 months, probably in the summertime. It is clear that the LLM area will likely be filled with competitors in the meanwhile, which can make for extra attention-grabbing shakeups on the Chatbot Area leaderboard within the months and years to come back.
On Tuesday, Anthropic’s Claude 3 Opus giant language mannequin (LLM) surpassed OpenAI’s GPT-4 (which powers ChatGPT) for the primary time on Chatbot Area, a well-liked crowdsourced leaderboard utilized by AI researchers to gauge the relative capabilities of AI language fashions. “The king is useless,” tweeted software program developer Nick Dobos in a put up evaluating GPT-4 Turbo and Claude 3 Opus that has been making the rounds on social media. “RIP GPT-4.”
Since GPT-4 was included in Chatbot Area round Could 10, 2023 (the leaderboard launched Could 3 of that 12 months), variations of GPT-4 have constantly been on the highest of the chart till now, so its defeat within the Area is a notable second within the comparatively quick historical past of AI language fashions. Considered one of Anthropic’s smaller fashions, Haiku, has additionally been turning heads with its efficiency on the leaderboard.
“For the primary time, the most effective obtainable fashions—Opus for superior duties, Haiku for price and effectivity—are from a vendor that is not OpenAI,” unbiased AI researcher Simon Willison advised Ars Technica. “That is reassuring—all of us profit from a range of prime distributors on this area. However GPT-4 is over a 12 months previous at this level, and it took that 12 months for anybody else to catch up.”
Benj Edwards
Chatbot Area is run by Giant Mannequin Techniques Group (LMSYS ORG), a analysis group devoted to open fashions that operates as a collaboration between college students and school at College of California, Berkeley, UC San Diego, and Carnegie Mellon College.
We profiled how the location works in December, however briefly, Chatbot Area presents a person visiting the web site with a chat enter field and two home windows exhibiting output from two unlabeled LLMs. The person’s process it to charge which output is healthier primarily based on any standards the person deems most match. By way of 1000’s of those subjective comparisons, Chatbot Area calculates the “greatest” fashions in mixture and populates the leaderboard, updating it over time.
Chatbot Area is vital as a result of researchers and customers alike usually discover frustration in making an attempt to measure the efficiency of AI chatbots, whose wildly various outputs are tough to quantify. In actual fact, we wrote about how notoriously tough it’s to objectively benchmark LLMs in our information piece concerning the launch of Claude 3. For that story, Willison emphasised the vital position of “vibes,” or subjective emotions, in figuring out the standard of a LLM. “Yet one more case of ‘vibes’ as a key idea in fashionable AI,” he stated.
Benj Edwards
The “vibes” sentiment is frequent within the AI area, the place numerical benchmarks that measure data or test-taking means are often cherry-picked by distributors to make their outcomes look extra favorable. “Simply had an extended coding session with Claude 3 opus and man does it completely crush gpt-4. I don’t suppose normal benchmarks do that mannequin justice,” tweeted AI software program developer Anton Bacaj on March 19.
Claude’s rise might give OpenAI pause, however as Willison talked about, the GPT-4 household itself (though up to date a number of occasions) is over a 12 months previous. At the moment, the Area lists 4 completely different variations of GPT-4, which symbolize incremental updates of the LLM that get frozen in time as a result of every has a novel output fashion, and a few builders utilizing them with OpenAI’s API want consistency so their apps constructed on prime of GPT-4’s outputs do not break.
These embody GPT-4-0314 (the “authentic” model of GPT-4 from March 2023), GPT-4-0613 (a snapshot of GPT-4 from June 13, 2023, with “improved perform calling help,” based on OpenAI), GPT-4-1106-preview (the launch model of GPT-4 Turbo from November 2023), and GPT-4-0125-preview (the newest GPT-4 Turbo mannequin, supposed to cut back instances of “laziness” from January 2024).
Nonetheless, even with 4 GPT-4 fashions on the leaderboard, Anthropic’s Claude 3 fashions have been creeping up the charts constantly since their launch earlier this month. Claude 3’s success amongst AI assistant customers already has some LLM customers changing ChatGPT of their each day workflow, probably consuming away at ChatGPT’s market share. On X, software program developer Pietro Schirano wrote, “Truthfully, the wildest factor about this complete Claude 3 > GPT-4 is how straightforward it’s to simply… change??”
Google’s equally succesful Gemini Superior has been gaining traction as effectively within the AI assistant area. That will put OpenAI on guard for now, however in the long term, the corporate is prepping new fashions. It’s anticipated to launch a significant new successor to GPT-4 Turbo (whether or not named GPT-4.5 or GPT-5) someday this 12 months, probably in the summertime. It is clear that the LLM area will likely be filled with competitors in the meanwhile, which can make for extra attention-grabbing shakeups on the Chatbot Area leaderboard within the months and years to come back.
On Tuesday, Anthropic’s Claude 3 Opus giant language mannequin (LLM) surpassed OpenAI’s GPT-4 (which powers ChatGPT) for the primary time on Chatbot Area, a well-liked crowdsourced leaderboard utilized by AI researchers to gauge the relative capabilities of AI language fashions. “The king is useless,” tweeted software program developer Nick Dobos in a put up evaluating GPT-4 Turbo and Claude 3 Opus that has been making the rounds on social media. “RIP GPT-4.”
Since GPT-4 was included in Chatbot Area round Could 10, 2023 (the leaderboard launched Could 3 of that 12 months), variations of GPT-4 have constantly been on the highest of the chart till now, so its defeat within the Area is a notable second within the comparatively quick historical past of AI language fashions. Considered one of Anthropic’s smaller fashions, Haiku, has additionally been turning heads with its efficiency on the leaderboard.
“For the primary time, the most effective obtainable fashions—Opus for superior duties, Haiku for price and effectivity—are from a vendor that is not OpenAI,” unbiased AI researcher Simon Willison advised Ars Technica. “That is reassuring—all of us profit from a range of prime distributors on this area. However GPT-4 is over a 12 months previous at this level, and it took that 12 months for anybody else to catch up.”
Benj Edwards
Chatbot Area is run by Giant Mannequin Techniques Group (LMSYS ORG), a analysis group devoted to open fashions that operates as a collaboration between college students and school at College of California, Berkeley, UC San Diego, and Carnegie Mellon College.
We profiled how the location works in December, however briefly, Chatbot Area presents a person visiting the web site with a chat enter field and two home windows exhibiting output from two unlabeled LLMs. The person’s process it to charge which output is healthier primarily based on any standards the person deems most match. By way of 1000’s of those subjective comparisons, Chatbot Area calculates the “greatest” fashions in mixture and populates the leaderboard, updating it over time.
Chatbot Area is vital as a result of researchers and customers alike usually discover frustration in making an attempt to measure the efficiency of AI chatbots, whose wildly various outputs are tough to quantify. In actual fact, we wrote about how notoriously tough it’s to objectively benchmark LLMs in our information piece concerning the launch of Claude 3. For that story, Willison emphasised the vital position of “vibes,” or subjective emotions, in figuring out the standard of a LLM. “Yet one more case of ‘vibes’ as a key idea in fashionable AI,” he stated.
Benj Edwards
The “vibes” sentiment is frequent within the AI area, the place numerical benchmarks that measure data or test-taking means are often cherry-picked by distributors to make their outcomes look extra favorable. “Simply had an extended coding session with Claude 3 opus and man does it completely crush gpt-4. I don’t suppose normal benchmarks do that mannequin justice,” tweeted AI software program developer Anton Bacaj on March 19.
Claude’s rise might give OpenAI pause, however as Willison talked about, the GPT-4 household itself (though up to date a number of occasions) is over a 12 months previous. At the moment, the Area lists 4 completely different variations of GPT-4, which symbolize incremental updates of the LLM that get frozen in time as a result of every has a novel output fashion, and a few builders utilizing them with OpenAI’s API want consistency so their apps constructed on prime of GPT-4’s outputs do not break.
These embody GPT-4-0314 (the “authentic” model of GPT-4 from March 2023), GPT-4-0613 (a snapshot of GPT-4 from June 13, 2023, with “improved perform calling help,” based on OpenAI), GPT-4-1106-preview (the launch model of GPT-4 Turbo from November 2023), and GPT-4-0125-preview (the newest GPT-4 Turbo mannequin, supposed to cut back instances of “laziness” from January 2024).
Nonetheless, even with 4 GPT-4 fashions on the leaderboard, Anthropic’s Claude 3 fashions have been creeping up the charts constantly since their launch earlier this month. Claude 3’s success amongst AI assistant customers already has some LLM customers changing ChatGPT of their each day workflow, probably consuming away at ChatGPT’s market share. On X, software program developer Pietro Schirano wrote, “Truthfully, the wildest factor about this complete Claude 3 > GPT-4 is how straightforward it’s to simply… change??”
Google’s equally succesful Gemini Superior has been gaining traction as effectively within the AI assistant area. That will put OpenAI on guard for now, however in the long term, the corporate is prepping new fashions. It’s anticipated to launch a significant new successor to GPT-4 Turbo (whether or not named GPT-4.5 or GPT-5) someday this 12 months, probably in the summertime. It is clear that the LLM area will likely be filled with competitors in the meanwhile, which can make for extra attention-grabbing shakeups on the Chatbot Area leaderboard within the months and years to come back.
















{kind=link}